



Strawberry Fields Forever
Deram um diploma de Phd pro ChatGPT. Conheça tudo sobre o novo modelo da OpenAI que promete mudar a forma com que interagimos com a inteligência artificial.


Essa é mais uma da série de conteúdos específicos do Trend Override, então para estar sempre up to date se inscreva aqui!
E se você tem aquele amigo que adoraria saber um pouco mais de inteligência artificial já compartilha esse post porque vai valer a pena!
12 de setembro de 2024, data que marca um grande dia para a inteligência artificial no mundo.
Tudo começou há alguns meses atrás, quando um perfil chamado iruletheworldmo no finado X (para brasil) começou a dar a entender que seria o próximo modelo da OpenAI por trás de seus posts. A foto, um tanto quanto sugestiva, nos dizia que algo teria a ver com o filme Her. Os mais esperançosos e otimistas sem dúvida já estavam com a crença em dia que chegaríamos a AGI em 2024!

Finalmente hoje a espera acabou. O tão aguardado novo modelo da OpenAI, que não é o ChatGPT 5, e nem se chama Strawberry, saiu. E tem mais algumas coisas sobre ele que você precisa saber antes da gente começar.
Ele marca uma mudança importante na forma que interagimos com a inteligência artificial;
Ele não irá custar dois mil dólares (como se especulava);
Mas também, ele não será disponibilizado gratuitamente como seus antecessores (está incluso para usuários do Plus);
Ele não é apenas mais um modelo de LLM;
Mas ele também não é AGI;
Vamos dar as boas vindas aos Reasoning models!
Esses modelos são treinados com aprendizado para realizar raciocínios complexos. Os modelos o1 pensam antes de responder e podem produzir uma longa cadeia de raciocínio interno antes de dar uma resposta ao usuário.
Vamos agora entender um pouco mais do porque hoje é um dia importante para a IA no mundo!
Como estamos falando especificamente da OpenAI, estarei analisando a evolução dos modelos do ChatGPT. Em se tratando de LLM, as referências usadas aqui serão válidas para qualquer modelo do mercado.
De 2018 para cá muita coisa mudou. Um pouquinho da evolução do que conhecemos hoje como ChatGPT:

Uma das coisas mais importantes de se observar na evolução de modelos é o número de parâmetros.
O que são parâmetros? Os parâmetros de um modelo de LLM (Large Language Model) são os valores numéricos que definem o comportamento do modelo. Eles são ajustados durante o processo de treinamento. Especificamente:
Representam o conhecimento e habilidades do modelo;
Determinam como o modelo processa e gera texto;
Os parâmetros incluem pesos das conexões entre neurônios artificiais e vieses nas redes neurais que compõem o modelo.
O ajuste fino desses parâmetros durante o treinamento permite que o modelo aprenda padrões complexos de linguagem e realize diversas tarefas relacionadas ao processamento de texto.
Tipos de parâmetros:
Pesos: São os valores que conectam diferentes "neurônios" no modelo. Eles determinam a importância de cada conexão.
Vieses: São valores adicionados às somas ponderadas em cada camada, permitindo que o modelo aprenda padrões mais complexos.
Distribuição dos parâmetros:
Estão distribuídos em várias camadas do modelo, como camadas de atenção, feed-forward, e embeddings.
A arquitetura do modelo (ex: Transformer) determina como esses parâmetros são organizados e utilizados.
Processo de aprendizagem:
Durante o treinamento, os parâmetros são ajustados iterativamente usando algoritmos de otimização.
O objetivo é minimizar a diferença entre as previsões do modelo e os dados reais de treinamento.
Impacto do número de parâmetros:
Geralmente, mais parâmetros permitem que o modelo capture padrões mais complexos.
Porém, isso também aumenta o risco de overfitting e a necessidade de mais dados de treinamento.
Chegamos então a conclusão que, mais parâmetros não necessariamente vão resultar em um modelo melhor. Ainda, muito mais que isso, não se acredita que chegaremos a AGI a partir de um modelo deste de linguagem. Precisaremos de mais!
Em resumo, o que os modelos como o ChatGPT fazem é selecionar a melhor próxima palavra dentro de uma resposta.
Por isso, existem várias técnicas que são usadas para extrair as melhores respostas. O “prompt engineering” estuda a melhor forma de realizar essas perguntas para o modelo.
Vamos exemplificar com três das técnicas mais famosas e que eu particularmente utilizo bastante:
Começar a resposta por ele. Dificilmente você não tem a menor ideia da resposta de algo que pergunta pro ChatGPT. Você começar a resposta de um prompt, ajudando ele a continuar da onde você parou, e assim aumentando a eficiência e qualidade das respostas produzidas pelo modelo.
Ter um melhor diálogo com a máquina. Dependendo do tema que esteja abordando, já existem diversos experimentos que mostram que a forma com que você pergunta interfere diretamente na resposta. Isso inclui emoção, entonação, linguagem, por exemplo. Para determinados assuntos, ser ultra simpático ajuda. Já para outros, ser mais ríspido é mais eficiente. Conhecer o modelo é fundamental para extrair boas respostas.
Ainda nessa linha, dar tempo para o modelo pensar, respirar, ter pausas também já é comprovadamente algo que ajuda em várias ocasiões. E é nesse ponto que vamos focar para apresentar o novo modelo da OpenAI.
Introducing: OpenAI o1

As mudanças começam pelo nome. Não será ChatGPT 5. Também não tem a proposta de ter mais parâmetros ou ser um ChatGPT 4 “melhorado”.
Sam Altman faz aqui um shift na empresa para outros tipos de modelo.
Hoje já se fala no mundo da tecnologia que, no futuro, os modelos de LLM serão commodities. Será difícil se diferenciar em alguns anos nesse segmento.
Abrir o leque para um novo tipo de modelo, mostra a preocupação da OpenAI em abordar a IA de outra forma.
Uma reclamação constante dos usuários é que, o ChatGPT prioriza o tempo de resposta, muitas vezes colocando em xeque a qualidade.
Os usuários mais técnicos da ferramenta muitas vezes não tem pressa, mas tem exigência.
Teoricamente estamos entrando na avenida que corrige esse percurso.
Desenvolvemos uma nova série de modelos de IA projetados para passar mais tempo pensando antes de responder. Eles podem raciocinar através de tarefas complexas e resolver problemas mais difíceis do que os modelos anteriores em ciência, programação e matemática. Hoje, estamos lançando o primeiro desta série no ChatGPT e em nossa API. Esta é uma prévia e esperamos atualizações e melhorias regulares. Junto com este lançamento, também estamos incluindo avaliações para a próxima atualização, atualmente em desenvolvimento.
Como funciona?
Treinamos esses modelos para passar mais tempo pensando sobre os problemas antes de responderem, assim como uma pessoa faria. Através do treinamento, eles aprendem a refinar seu processo de pensamento, tentar diferentes estratégias e reconhecer seus erros.
Em nossos testes, a próxima atualização do modelo tem desempenho semelhante ao de estudantes de doutorado em tarefas desafiadoras de referência em física, química e biologia. Também descobrimos que ele se destaca em matemática e programação. Em um exame de qualificação para a Olimpíada Internacional de Matemática (IMO), o GPT-4o resolveu corretamente apenas 13% dos problemas, enquanto o modelo de raciocínio obteve 83%. Suas habilidades de programação foram avaliadas em concursos e alcançaram o 89º percentil em competições do Codeforces. Você pode ler mais sobre isso em nossa postagem de pesquisa técnica.
Como um modelo inicial, ele ainda não tem muitos dos recursos que tornam o ChatGPT útil, como navegar na web em busca de informações e fazer upload de arquivos e imagens. Para muitos casos comuns, o GPT-4o será mais capaz no curto prazo.
Mas para tarefas de raciocínio complexo, este é um avanço significativo e representa um novo nível de capacidade de IA. Diante disso, estamos reiniciando o contador de volta para 1 e nomeando esta série OpenAI o1.
Esse texto, traduzido do e-mail de boas vindas da OpenAI, mostra que eles estão indo para a linha técnica da coisa.
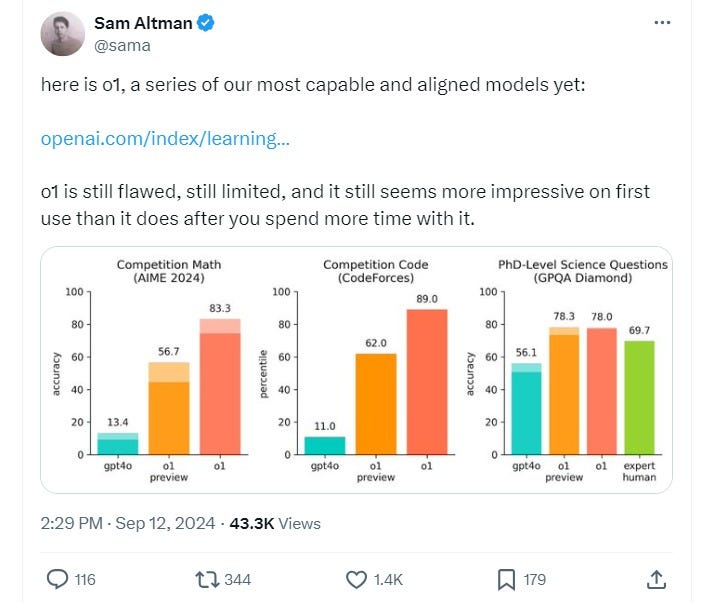

A palavra que vamos passar a escutar muito agora é: Reasoning
Isso porque estes modelos vem preparados e programados para pensar e resolver tarefas muito mais complexas que os modelos anteriores.
Isso promete otimizar melhor os modelos. Você não precisa de um Phd para saber qual a capital da Suíça. Mas uma pessoa comum também não vai conseguir ajudar um médico em sua pesquisa de doutorado.
Com a introdução desse novo tipo de modelos, começamos a setorizar melhor as coisas.
Mas então, a pergunta que eu mais recebi hoje: Posso usar o novo modelo igual eu usava o ChatGPT e terei respostas melhores?
A resposta é: NÃO!

A forma que iremos interagir com estes modelos precisará ser diferente. Segundo a própria OpenAI:

Já tem até alguns posts engraçados de usos erráticos do modelo:
Parte do que este modelo está fazendo é realizar uma engenharia de prompt para o usuário. Essa é uma aposta grande que eu tenho para os próximos modelos que irão surgir. Não é todo mundo que irá querer estudar engenharia de prompt mas as pessoas também não vão querer respostas simples como as dadas por uma plataforma como Perplexity.
A trajetória da OpenAI chega em uma bifurcação em um momento importante da história.
Alguns dias atrás, estávamos nós aqui discutindo se a OpenAI iria mesmo com todas as fichas para cima do Google para entregar um novo buscador.
Agora, fizemos um u-turn e chegamos com um produto totalmente técnico, nos moldes dos antigos produtos do Google especializados em ciência.
Especula-se que hoje o uso do ChatGPT ainda seja majoritariamente superficial, para fazer perguntas de cunho simplista. Neste caso, eu arrisco dizer que o o1 irá piorar a experiência do usuário.
No curtíssimo prazo isso fortalece plataformas mais focadas em respostas diretas e rápidas como o Perplexity.
Na geração TikTok, poucas pessoas querem esperar 10 segundos por uma resposta. Daí inclusive vem grande parte do sucesso do ChatGPT original.
MAS, isso abre uma nova gama de possibilidades de uso. Não só os usos que foram divulgados oficialmente nos campos de ciências e computação, mas como verdadeiros aliados a produtividade.
Assim que o modelo saiu, eu fiz uma brincadeira de pegar o código que eles mostram no vídeo demonstração do produto para criar um game, e rodei ele em outra LLM para gerar o mesmo jogo. O meu resultado ficou assustadoramente pior!
O vídeo original:
Meu teste:
É claro que esse teste é uma brincadeira, em menos de 6 horas que o modelo foi lançado já temos uma penca de testes bem mais legais que esse na internet.
Essa parte de desenvolvimento sem a necessidade de saber código pode mudar muito a forma com que as pessoas irão interagir com a máquina.
Esse post foi só para contar um pouco das possibilidades que se abrem com a introdução do o1.
A partir desse momento irei começar a postar também mais exemplos e aplicações no mundo real do que esses modelos podem fazer.
Conto com você nessa!
Abs e boa sexta para todos!