

Searching... Seek and destroy
Um pouco de história, muita confusão e uma dose de otimismo. O que esperar de 2025 pós DeepSeek?


Essa é mais uma da série de conteúdos especiais do Trend Override, então para estar sempre up to date se inscreva aqui!
Eu sei, ninguém aguenta mais falar de DeepSeek e como ele supostamente enterrou os atuais modelos de LLM.
Como todos outros detentores de newsletters de mercado e tecnologia, passei os últimos dias debruçado em entender e estudar os impactos do que aconteceu no mercado.
Precisei de um tempo para estruturar meu racional, então, vamos lá.
Views aqui são minhas com base em inúmeros textos, vídeos e posts do X que li nos últimos dias!

O carvão de 2025
Vários “fenômenos” históricos podem ser atribuídos ao que aconteceu, desde o Paradoxo de Jevons até a enxurrada de produtos chineses em todos os tipos de mercado.
Assim como hoje os chips da NVIDIA são o combustível de todo processamento de inteligência artificial, quem desempenhava esse papel da década de 1800 era o carvão.
O que é, então, este paradoxo?
O paradoxo de Jevons afirma que, à medida que as melhorias tecnológicas aumentam a eficiência com a qual um recurso é usado, o consumo total desse recurso pode aumentar em vez de diminuir. Em particular, este paradoxo implica que a introdução de tecnologias mais eficientes do ponto de vista energético pode, no conjunto, aumentar o consumo total de energia.[1] Isso também é conhecido como efeito rebote.
Ou seja, a medida que uma tecnologia se torne mais eficiente, o custo cai e o consumo aumenta.
E isso é uma boa notícia para todo ecossistema da IA.
O DeepSeek destravou uma nova forma de processar IA, aplicando o famoso conceito de fazer mais com menos. Quantas iniciativas de IA hoje não estão sendo implementadas pelo fator custo? É um compromisso do próprio Sam Altman tornar o ChatGPT “mais barato”. Mais aplicações, mais empresas, mais acesso, certamente irão resultar em mais chips da NVIDIA. O problema talvez esteja na projeção, mas não no DeepSeek!
Quem usou este paradoxo para exemplificar o que está acontecendo foi Satya Nadella, da Microsoft:
“To see the DeepSeek new model, it’s super impressive in terms of both how they have really effectively done an open-source model that does this inference-time compute, and is super-compute efficient. We should take the developments out of China very, very seriously”
Copiar para aprender e aprimorar…
O que pode acontecer com o mercado de modelos de IA é o que já aconteceu em diversos outros mercados.
Drones
Algo em torno de 90% de todos os drones de consumo são fabricados na China. Inclusive os que o exército dos EUA utiliza. Trata-se de todo o ecossistema, todos os componentes. A FAA do governo Biden tem tentado acabar com a indústria de drones dos EUA como parte de sua guerra contra a tecnologia. A China agora está sancionando as empresas de drones dos EUA devido às baterias fabricadas na China. Eles têm poder de influência.Carros
A cadeia de suprimentos de drones é análoga à cadeia de suprimentos de carros. Os novos carros chineses que estão sendo lançados são realmente bons e têm uma enorme vantagem em custo.Robôs
Os chineses estão à frente dos EUA em 100% no mercado de robôs. Embora os americanos tenham a liderança em P&D, os chineses possuem quase total domínio na capacidade de fabricação, com milhares de empresas que fabricam todos os componentes necessários para os robôs.
Para se ter uma noção de como a China leva a sério o conceito de fazer mais com menos, o robô SPOT da Boston Dynamics (já falei dele no Trend Override) custa US$ 50.000. A China tem um produto semelhante, que se parece e age de forma parecida, é integrado com um modelo de linguagem (LLM) e custa apenas US$ 1.500.
Grande parte do que usamos hoje vem da China. Alguns nos dizem isso explicitamente, outro optam por um caminho, digamos, mais sutil 🤗

Open-Source everything
Falando em Apple, o ChatGPT está seguindo um caminho parecido. Manter seus modelos no formato “blackbox”, onde o usuário não tem muita ideia e tampouco consegue influenciar no que sai de lá. Eles apostam que manter seu ecossistema fechado vai lhes garantir mais confiabilidade e, assim, aumentar cada vez mais sua base de usuários. Mas, isso tem sido entregue a um alto custo.

Se você, assim como eu, agradece todo dia pela existência destas ferramentas, algumas pessoas do universo tech demonstram algumas nobres preocupações com relação a elas.
Todos capítulos da novela OpenAI, CloseAI, Sam x Elon, etc… foram amplamente cobertos aqui por esta news.
Na opinião de muitos, a OpenAI não tem nenhum interesse em fazer nada para o bem das pessoas. Muitos, inclusive, se mostram desconfortáveis em compartilhar suas informações com ela.
Ah, mas usando o DeepSeek você compartilha suas informações com o governo Chinês.
Isso pode não ser verdade, graças ao open-source.
Assim como os telefones Android da Samsung e LG por exemplo. Como o sistema operacional bruto é também open-source, o que as grandes marcas fazem é adicionar camadas de customização em cima do código aberto inicial do sistema.
Com o DeepSeek é a mesma coisa. Hoje, por exemplo, podemos usar tranquilamente o modelo R1 por plataformas como Perplexity. O que empresas como essa fazem é rodar o código do modelo dentro do ecossistema delas, sem nenhuma conexão com a China, neste caso particular.
Mas, importante reforçar: Considerando a política da empresa, suas informações podem sim ser compartilhadas com entidades da China, governamentais ou não, caso você opte por usar o modelo diretamente no site ou app DeepSeek! =)
Offline mode
Para o uso doméstico, acredito que grande parte das pessoas não esteja muito preocupada com o compartilhamento de dados. Seja com a China, com a Meta, Google, ou whatever…
Mostrar isso é bem simples, qual foi a última vez que você leu os termos e condições de algum app?
Mas, quando tratamos de empresas, dados sigilosos ou governamentais, por exemplo, a coisa muda um pouco de figura.
E por mais que as plataformas fechadas como a OpenAI tenham planos empresariais, teoricamente mais aderentes as regras de compliance, modelos como o DeepSeek chegam para nos encher de esperanças.
Já existem diversos testes na internet de pessoas rodando o modelo chinês com um conjunto de MacMini’s (4 para ser preciso), ou em computadores equipados com NVIDIA que foram montados com aproximadamente 6 mil dólares.
A Apple, por sinal, foi uma vencedora silenciosa dentro desse caos. Isso porque eles são detentores de uma tecnologia chamada UltraFusion, na qual processadores de diferentes Mac’s podem se conectar com baixa latência. Isso, somado ao fato do Apple Silicon usar memória unificada para processamento, faz essa combinação de vários Mac’s serem um ambiente excelente para rodar estes modelos de forma offline!
Hoje é possível também alugar máquinas com grande capacidade de processamento na nuvem, que podem ser usadas remotamente para rodar o modelo de forma totalmente offline.
Eu acho que vamos ver um crescimento muito grande de aplicações utilizando essa modalidade. Pensando até em níveis educacionais, restringir esse tipo de informação, pode ser muito positivo se feito corretamente.
Brevidades sobre DeepSeek
Nesse momento a história da empresa já está contada, e não vou me aprofundar em detalhes aqui.
É um resumo de um caso que o mundo tech adora: Um garoto em uma garagem que pode arruinar um negócio.
Neste caso o garoto são pouco mais de 200 funcionários (versus 4000 da OpenAI) e a garagem é o spin-off de um fundo quantitativo chinês chamado High-Flyer.
O objetivo: Chegar a AGI antes dos EUA com um custo muito menor
A estratégia: Tentar um caminho diferente das concorrentes buscando aumentar a eficiência dos modelos por um custo menor.
A maior dificuldade: A limitação regulatória de quantos chips NVIDIA se pode importar e usar em solo chinês (atualmente 50,000 GPUs).
Os modelos da empresa ganharam rapidamente a atenção do mercado. O R1 Lite, lançado em novembro de 2024, já havia sido muito bem recebido, tirando inclusive notas superiores ao o1 da OpenAI em diversos testes.
Chegamos então a um novo conceito no mundo da IA: “Mais investimento não significa necessariamente mais inovação.” E sobre isso, o CEO da empresa, Liang Wenfeng, declarou:
“Atualmente, não vemos novas abordagens, mas as grandes empresas não possuem uma vantagem clara. Embora tenham clientes existentes, seus negócios de fluxo de caixa podem se tornar um fardo e deixá-los vulneráveis à inovação a qualquer momento.”
Sobre o atraso no lançamento do GPT-5, ele acrescentou:
“A OpenAI não é um deus e não precisa estar sempre na vanguarda.”
Embora não seja o que Sam Altman pense a respeito disso…
Autodidata
Uma das coisas que mais chamou atenção no DeepSeek foi o fato dele ter sido treinado com o método “Reinforcement learning”, ao contrário dos modelos da OpenAI e Anthropic que tiveram supervisão humana. De forma simplista, isso quer dizer que o modelo chinês aprende a raciocinar naturalmente!
É como se uma criança tivesse tentando resolver um problema sozinha e fosse aprendendo a cada tentativa.
E aqui é mais uma boa notícia para o mercado de modelos LLM, em especial os de reasoning. Agora, é uma questão de tempo até OpenAI, Google, Anthropic e Microsoft virem a público com modelos treinados usando esse método. Lembrando que, como essas empresas tem um poder computacional infinitamente maior (motivo principal de estar escrevendo esse texto), elas podem surpreender e entregar resultados muito bons em um tempo muito curto!
Outra nota importante: As sanções americanas para a china continuam valendo. Isso tende a frear o desenvolvimento das tecnologias chinesas, deixando a pista livre para os americanos entregarem seus modelos!
2x mais rápido em 24 horas
Prova mais que viva que ele aprende sozinho, e rápido, é que no seu segundo dia de lançamento a empresa anunciou um “2X speed boost”, que entregava as repostas com a mesma qualidade, duas vezes mais rápido.
Mas, o que chocou mesmo foi o fato do código para desempenhar essa tarefa foi feito pelo próprio R1! Foi o primeiro caso emblemático de Self-improving AI!
SKYNET is here!!!!

Números não mentem…
Enquanto a quantidade de GPUs e o valor investido são totalmente questionáveis, os outputs do modelo, por outro lado, não são:
671B parâmetros (apenas 37B ativados por consulta).
14,8T tokens nos dados de treinamento.
Dominância em benchmarks: Superou os últimos modelos da OpenAI em testes-chave (AIME 2024, MATH-500, SWE-Bench).
O carvão virou chip
Dylan Patel, da SemiAnalysis, apontou isso desde junho. Isso não significa o fim da necessidade de mais poder computacional, ou que o player mais intensivo em capital não vencerá. DeepSeek teve que buscar alternativas devido as restrições de importações de chips NVIDIA impostas pelos EUA. Isso fez com que eles acabassem encontrando um caminho mais eficiente:
“O DeepSeek V2 demonstrou eficiência de treinamento surpreendente, alcançando um desempenho de modelo melhor do que outros modelos abertos com 1/5 do poder computacional do Llama 3 70B da Meta. Para contextualizar, o treinamento do DeepSeek V2 exigiu apenas 1/20 dos FLOPs do GPT-4, enquanto entregava desempenho comparável.”
A bolha estourou?
O impacto no mercado foi selvagem. Como falamos no começo dessa conversa, a maior dúvida não é sobre os carros, mas sim, sobre o combustível. E, assim, as ações da NVIDIA foram as grandes perdedoras do dia.

Vi muitas entrevistas com fundos brasileiros e gringos. A primeira ordem, em muitos casos, foi vender para entender. Talvez o preço para isso seja alto, ou não, mas é uma política que as casas, em geral, precisam seguir.
Perguntei para o DeepSeek o que ele achou dessa reação de mercado, e essa foi sua análise na íntegra:
A queda de quase 20% nas ações da Nvidia após o lançamento da DeepSeek reflete uma combinação de fatores racionais e reações imediatistas do mercado, com nuances que exigem análise detalhada:
Contexto da reação do mercado
Impacto imediato da concorrência chinesa
A DeepSeek demonstrou capacidade de desenvolver modelos de IA avançados com custos 90% menores que os tradicionais (US$ 6 milhões vs. US$ 50-100 milhões)25. Essa eficiência operacional desafiou diretamente o modelo de negócios da Nvidia, baseado em hardware caro e especializado16.Magnitude das perdas financeiras
Fatores que justificam a reação
Risco estratégico comprovado
A DeepSeek já liderava rankings de downloads na App Store chinesa7 e demonstrou capacidade de operar em hardware antigo5, potencialmente reduzindo a necessidade de upgrades constantes de GPUs.Dependência excessiva do setor de IA
47% da receita da Nvidia vem de soluções para inteligência artificial6, tornando-a vulnerável a disrupções nesse segmento.Efeito dominó no mercado
A queda arrastou índices como Nasdaq (-3.1%) e S&P 500 (-1.8%)1, indicando percepção sistêmica de risco.
Elementos de possível exagero
Resposta tecnológica iminente
A Nvidia já apresentou na CES 2025 as GPUs RTX 50 com arquitetura Blackwell, prometendo 200% mais performance que a geração anterior11, e mantém liderança em DLSS 4.010.Barreiras geopolíticas
Restrições norte-americanas à exportação de chips podem limitar a expansão global da DeepSeek2, protegendo parte do mercado da Nvidia.Recuperação parcial
Após a queda inicial de 17%, as ações recuperaram 5.4% no pré-mercado do dia seguinte4, mostrando resiliência relativa.
Perspectivas de médio prazo
A Nvidia enfrenta um dilema estratégico:
Ameaças: Necessidade de reduzir custos de produção sem comprometer performance
Oportunidades: Expansão em mercados emergentes com a linha RTX 5070/5080 (US$ 799-1,999)11 e parcerias em cloud gaming via GeForce Now910.
Embora a reação do mercado pareça desproporcional frente ao histórico de inovação da empresa, o episódio expôs vulnerabilidades críticas num setor onde a hegemonia tecnológica é constantemente contestada. A capacidade de adaptação da Nvidia aos novos paradigmas de custo-efetividade determinará se esta queda representa um revés temporário ou uma mudança estrutural no setor56.
Winner takes all?
Com as cartas que temos na mesa, a resposta é simples: Não!
O objetivo não é apenas um modelo de raciocínio, mas AGI (Inteligência Artificial Geral) e ASI (Inteligência Artificial Superinteligente).
No entanto, o DeepSeek mostra uma coisa: o custo da inteligência está caminhando para zero.
E isso é muito mais importante do que a questão de quão caro é treinar os modelos.
Lembrando onde começamos este texto:
Custos mais baixos → maior adesão e distribuição —> aplicação muito mais ampla —> mais computação —> mais usuários.
“Eu já sabia” Karp, Alex
A Palantir tem alertado há meses que o valor da IA não permanecerá nos modelos – ele se deslocará para as aplicações, fluxos de trabalho e segurança.
"As pessoas estão equivocadas. Elas acham que todo o valor está nos LLMs.
Os modelos de IA são como hidrocarbonetos no solo.
Eles precisam ser processados."
Tudo isso reforça a visão de Karp de que o valor está na camada de aplicação e fluxo de trabalho.
Batata quente
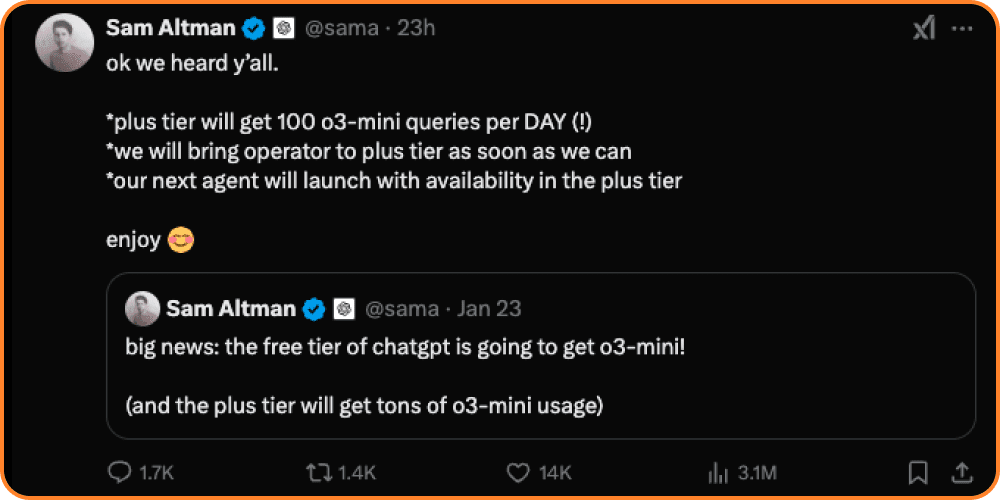
Essa história colocou uma dúzia de batatas, bem quentes, nas mãos de todos. Podemos esperar uma enxurrada de modelos de IA saindo nos próximos dias e semanas. O próprio Sam Altman já anunciou algumas novidades:
O CEO da Perplexity, por outro lado, além de muito animado, está usando a falta de capacidade da matriz chinesa de atender os usuários pelo mundo:
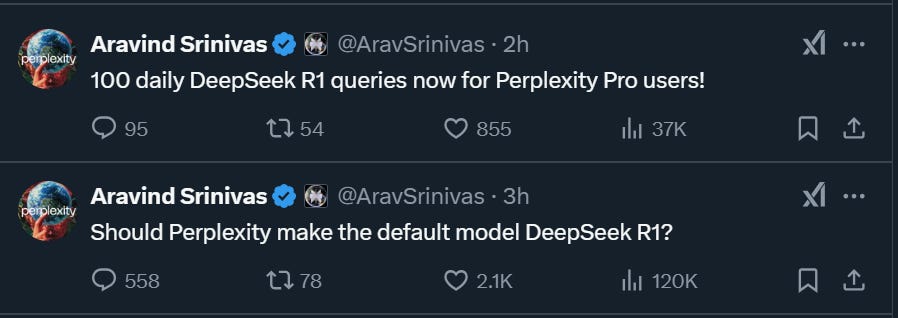
Não preciso dizer que, após chegar a primeira posição nos downloads da App Store, o DeepSeek ficou rapidamente indisponível devido a alta demanda, tendo seu acesso restrito para usuários com um telefone na china. Testei usando VPN de alguns países, funcionou até domingo e depois mal consegui usar (estou usando via Perplexity, se você tem Vivo, pode acessar o Pro gratuitamente - deixe um comentário caso não saiba fazer!)
Quem também se posicionou foi o Amodei, CEO da Anthropic. Dentre tudo que já falamos aqui, ele reforçou a posição das empresas que tem um grande poder computacional e que podem ainda melhorar muito o que foi feito pelo DeepSeek!
Easter egg
Pesquisadores da empresa de segurança em nuvem Wiz publicaram descobertas que sugerem que o DeepSeek deixou um de seus bancos de dados críticos exposto na internet, vazando logs do sistema, submissões de prompts dos usuários e até tokens de autenticação API dos usuários - totalizando mais de 1 milhão de registros - para qualquer pessoa que encontrasse o banco de dados.
Um destes vazamentos sugere também que eles utilizaram os modelos da OpenAI para treinar os seus.


Essa é uma história em desenvolvimento, certamente teremos diversos acontecimentos e voltaremos aqui muitas vezes ainda esse ano!